Machine learning models are designed to make predictions, and one key factor in evaluating their performance is how well they classify data. When it comes to classification models, two metrics that frequently come up are Precision and Recall. These two terms are often used interchangeably, but they represent distinct aspects of model performance.
Understanding the difference between the two is crucial for selecting the right evaluation metric based on the problem you're trying to solve. In this article, we will break down Precision vs. Recall, explore their pros and cons, and explain how to determine which metrics best suit your machine-learning task.
What is Precision?
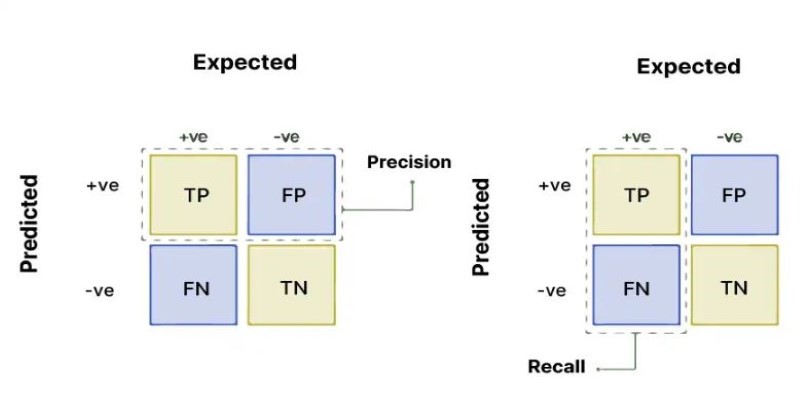
Precision is a measure to assess how accurate positive predictions from a machine learning model are. Simply put, it asks: Out of all the cases the model predicted as positive, how many were indeed positive?
Mathematically, precision is defined as:
Where:
- True Positives (TP): The instances that were correctly predicted as positive.
- False Positives (FP): The instances that were incorrectly predicted as positive.
For instance, if you're creating a spam email filter, precision would gauge how many of the emails that the model marked as spam actually are spam. High precision means that when the model says an email is spam, it is probably spam.
Pros of Precision

Precision is highly important in contexts where false positives are expensive. For instance, in diagnostics in medicine, classifying a healthy patient as ill could lead to unnecessary procedures and treatments. High precision makes it very likely to be true when a positive prediction is made, reducing the need for unnecessary actions. This is particularly useful in fraud detection or safety-critical applications, where it's extremely important to aggressively mark only true positives and never generate false alarms, keeping resources targeted at confirmed, high-risk cases.
Cons of Precision
Although precision is desirable, emphasizing it excessively can lead to false negatives and missed actual positives. Optimizing for precision causes the model to be overly careful, generating fewer positive predictions in total. This can reduce recall, or the model may not recognize many relevant instances. For example, in diagnosis, if the model is only predicting positives for the most evident cases, it could overlook early-stage illnesses. Thus, precision may not be enough when identifying all possible positives, which is important, as recall also must be taken into account.
What is Recall?
Recall, on the other hand, focuses on how well the model identifies all the actual positive instances in the dataset. It answers the question: Out of all the instances that were actually positive, how many did the model correctly identify?
Mathematically, recall is defined as:
Where:
- True Positives (TP): The instances that were correctly predicted as positive.
- False Negatives (FN): The instances that were incorrectly predicted as negative.
In the case of a medical diagnosis model, recall tells us how many sick patients the model correctly identified. A high recall score means that the model successfully detects most of the actual positive cases, even if it also makes some mistakes in predicting positives.
Pros of Recall
Recall is essential when the cost of missing a positive instance is high. For instance, in the context of detecting a disease, missing a sick patient (false negative) could be catastrophic, whereas incorrectly diagnosing a healthy patient as sick (false positive) might be less severe.
A high recall ensures that most of the true positives are captured, which can be crucial in situations where false negatives could lead to harmful consequences. For example, recall is often prioritized in tasks like fraud detection or identifying rare, high-impact events, where it's important not to overlook any potential cases.
Cons of Recall
The major drawback of focusing on recall is that it can lead to an increase in false positives. To capture more positive cases, a model might become more lenient in predicting positives, which can lead to incorrectly predicting negatives as positives. As a result, this can reduce the precision of the model.
For example, in a spam filter, if the model tries to capture as many spam emails as possible, it might flag many legitimate emails as spam, reducing the overall precision.
Key Differences: Precision vs. Recall in Machine Learning
Understanding the fundamental differences between precision and recall is crucial for optimizing machine learning models.
Focus on False Positives vs. False Negatives:
Precision reduces false positives, ensuring accurate positive predictions. Recall minimizes false negatives, capturing all true positives even if false positives increase. The choice depends on whether missing or incorrectly identifying positives is more critical.
Impact on Model Behavior:
High precision makes a model conservative, predicting fewer positives with greater accuracy. High recall makes it lenient, capturing more positives but increasing false positives. The trade-off influences model reliability based on whether accuracy or completeness is more important.
Application Context:

Precision matters in fraud detection, where false positives are costly. Recall is crucial in medical diagnoses, preventing missed conditions. Choosing precision or recall depends on the consequences of errors, ensuring models align with real-world needs and risks.
Harmful Consequences of Misclassification:
Precision may miss true positives, while recall risks misclassifying negatives as positives. Precision ensures correct positive predictions but might overlook some cases. Recall captures most positives but raises false alarms, affecting decision-making in critical applications.
Trade-off Between Precision and Recall:
Increasing precision often reduces recall and vice versa. Finding an optimal balance is crucial. The F1 score helps evaluate models where both are important, ensuring an effective compromise between accuracy and comprehensive detection of positive cases.
Conclusion
Both precision and recall are essential for evaluating machine learning models, each focusing on different aspects of model performance. Precision minimizes false positives, while recall aims to reduce false negatives. The trade-off between these two metrics can be managed using the Precision-Recall Curve and balanced through the F1 score. Depending on the application, choosing the right metric is crucial to optimize model performance and achieve the desired results without compromising on important predictions.